编者按:本文来自万向区块链,Odaily星球日报经授权转载。本文为万向区块链蜂巢学院线上公开课第二十九期的分享内容。本期邀请了安比实验室创始人郭宇,带来分享《当深度神经网络遇上零知识证明》。

今天跟大家一起交流下「当深度神经网络遇上零知识证明」。零知识证明

「零知识证明」这个概念在区块链底层技术架构里并不陌生,它是在1985年时由Goldwasser、Micali和Rackoff三人提出。虽然长期以来「零知识证明」只是局限在计算理论研究里的一个小领域,但是它带来的影响非常深远。零知识证明里面有个词「证明」,这个概念在整个人类文明发展历史中经过了很多次范式转换。在古希腊,「证明」是一种巧妙的数学技巧;到20世纪初,数学证明在第三次数学危机中被重新诠释,引入形式逻辑被形式化,因而从此诞生了计算理论与计算机。到70年代,程序和证明之间的奇妙关联被发现,现代函数式编程与自动定理证明的很多概念被引入;到80年代,「证明」的概念被延伸到了交互系统。到了80年代之后交互式证明系统无论是从哲学意义上,还是从理论技术方面,都带来了革命性的新的见解。在我第一次看到零知识证明概念的时候,第一反应是这个东西非常反直觉。为什么「反直觉」?我先来简单介绍一下零知识证明基本的框架。
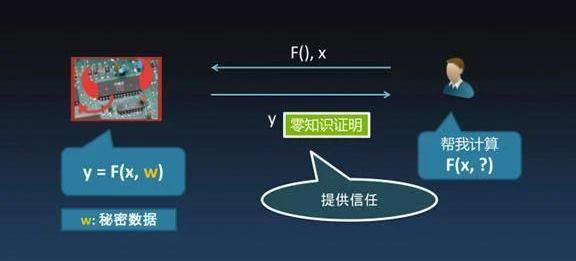
在零知识证明中一定有像右边这样一个人,我们把他称之为Bob,左边可能是一台不受信任的机器。此时,假如说Bob有一个计算任务要交给左边的机器来运行,但这机器本身可能会受人控制。Bob需要把一个「F」函数作为计算任务,带上输入「X」,交给左边机器,让它去完成这个计算任务。因为这个计算过程发生在左边的机器上,对于Bob来说并没有见证整个计算过程,那Bob凭什么相信计算结果Y=F的式子能成立呢。并且运算过程中掺入了一些只有左边机器知道的秘密数据,而Bob并没有W,因而Bob是不能通过复现计算过程来获知计算结果是否正确。在这样的情况下,能不能让Bob还能相信计算结果是对的呢?一句话,零知识证明能够神奇地让Bob相信计算结果是正确的。这听上去有点不可思议,信任计算结果Y是基于对左边机器的不信任,也就是说零知识证明它凭空地产生了一些信任,这正是反直觉所在。设想一下,在两个人互相完全不信任的情况下,居然可以通过某种东西建立信任,这点是非常非常有趣的。反直觉的零知识证明我总结一下,它可以这么来理解:可以保证一个远程计算过程的完整性与机密性。1、完整性。虽然我没有看见在远程发生的计算过程,虽然没有见证它的过程,但知道这计算过程一定是真实发生过的,而且计算结果是正确的,也就说计算过程并没有被恶意的修改或者是被伪造。2、机密性。虽然我见证不了计算过程,同时不可能知道计算过程中的一些中间结果,也不可能知道它内部的一些信息,所以说整个计算过程,包括一些秘密输入,对我来说是机密的、保密的。这就是反直觉零知识证明所能达到的效果。零知识证明到底有什么用处呢?我觉得最直接的用处就是所谓的「数据隐私保护」。我简单列了一些,例如个人数据:健康数据、银行流水、出行安排、通信记录。其实我们是不想让任何人知道我们的健康状况,包括心跳、医疗记录,也不想让人知道每天花了多少钱。但是我们又想享受第三方的服务,比如说出门打车,想让有些人知道自己在哪,但又不想让其他人知道,或者说只想让他知道一个大概的地方,不想让他知道具体的位置。企业数据:人事档案、仓储物流、财务账本、客户信息,传统意义上这些都是非常机密的数据,但是为了能够最大发挥企业间协作的效果,必须要共享一部分数据。零知识证明提供了一种既能够保证数据的隐私,同时还能共享数据的方式,所以说它对我们未来生活、工作的最大影响就是能够提供非常有效的数据隐私保护技术。零知识证明在区块链底层技术中还有很多有趣的用处,自从1985年零知识证明被提出来之后,它长期停留在理论结果层面,直到区块链技术得到大规模应用之后,大概自2015年-2020年,零知识证明在区块链上得到了广泛的应用。包括区块压缩、保护交易匿名性、身份隐私、共享数据、链下数据存储完整性等等之类,在区块链行业的技术朋友们应该对这些都不太陌生。接下来介绍两个很基本的概念。非交互式的零知识证明我们前面讲过,零知识证明提出来的时候对「证明」的范式做了全新的革新,以前证明是写在纸上,比如说老师出了一道题考试,要证明它,要把证明过程写出来。而零知识证明是一种交互式证明,通过和老师对话,可以在不告诉老师任何证明过程的情况下让老师相信我。为什么又有了非交互式零知识证明呢?非交互式零知识证明是用一些特殊的技巧,能够把交互式的证明过程折叠成非交互式的零知识证明。非交互零知识证明在区块链领域的应用更加广泛。zkSNARK这也是一个很常见的词,当然它在学术领域也有很多不那么一致的解释。不严谨的说,zkSNARK是一种特殊的NIZK,即特殊的非交互式零知识证明,特殊在哪呢?下面列了三点:1、简洁。它生成的证明非常小,有多小呢?通常是KB量级,甚至可以小到200个字节以内。别看只有这几百个字节,但它能代表的计算过程可以非常非常庞大,它所能保护的数据也可以是上TB量级的。2、Argument。是零知识证明的一种,稍后会简单解释下。3、zkSNARK最后有一个「K」,就是Knowledge的意思。含义是证明是关于「knowledge」的证明,这个「knowledge」是有一个数学定义。隐私保护、区块链与零知识证明
Web3初创公司nealthy完成130万美元pre-seed轮融资:3月7日消息,Web3初创公司nealthy宣布完成130万美元pre-seed轮融资,“DonGeraldo”等天使投资人参投。Nealthy 的创始人将利用这些资金来发展核心团队、聘请人才并促进销售和发展。
nealthy通过区块链技术处理交易并提供指数代币,使投资者能够快速、无忧地进入Web3市场,该指数代币通过存储多种虚拟资产“复制”了传统ETF结构。此外,nealthy还推出了首个动态蓝筹NFT代币“NFTS” ,预计在2023年夏季发布。[2023/3/7 12:47:46]
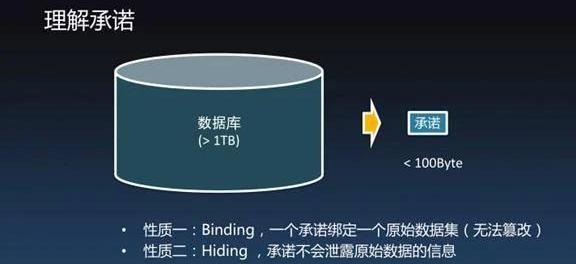
讲这个概念之前先要讲一个非常重要的密码学概念——承诺。如图,大家可以看到左边是一个数据库,这个数据库非常非常大,可能是超过1TB那么大,可以用密码学的手段把它变成很小很小的一段字节,大概小于100字节。不管这个数据库多大,最后承诺都可以压成不超过100字节这么大的数据。别看只有100多个字节,它可以和数据库建立唯一的绑定关系,如果当数据库里发生任何的改变,这个承诺就必须跟着一起改变。承诺就好比是「一把锁」,只要有人把承诺记下来之后,数据库只要有任何的修改,承诺就会发生巨大的变化。承诺有两个性质:性质一:Binding,一个承诺绑定一个原始数据集。这个数据集可能非常大,但可以用一个非常小的承诺给绑定起来。性质二:Hiding,承诺不会泄露原始数据的信息。因为只有100个字节左右,所以没有泄露任何的原始数据信息,因为信息量已经被大量的损耗了。假如有很多数据库,比如说出行记录、银行各有一个数据库,可以生成两个承诺,然后把承诺上链,当把承诺放在区块链上之后就会有一个效果,就是再也不能反悔去修改数据库了,但把承诺上链之后可以给大家看,大家可以通过承诺访问数据库,当然是有选择性的开放,或者把数据库的数据做一些处理之后开放。但因为有这个承诺被锁定在链上,所以说不可能作弊。把数据交给另外一个人之前可以做很复杂的处理,可以把里面的敏感数据删掉,这么做一定是非常诚实,并没有造假的,因为承诺在链上。承诺听上去也挺神奇,却是很传统很常用,但是非专业人士了解很少的的密码学工具。承诺其实有很多种实现方法,最简单的是可以用一些像Hash运算。还有MerkleTree、PedersenCommitment或者是PolynomialCommitment、ElgamalEncryption,这些都是能实现承诺。承诺中有两类很关键,这是从密码学理论的角度来分析:第一类:ComputationalBindingandPerfectHiding。第二类:PerfectBindingandComputationalHiding。所谓的PerfectHiding就是承诺绝对不可能泄露一丝一毫,完美的隐藏了原始数据,但它的绑定关系是Computational,如果想象未来100年后有人拥有超级量子计算机,它远超现在的计算能力,那时候就可以造假,伪造一个和原数据不关联的假承诺。另外一类是反过来的,它的绑定关系是PerfectBinding,有超级量子计算机也不可能去造假,但是它的Hiding是Computational,也就说如果100年以后有超级量子计算机出来之后可以破解现在产生承诺,并能够从中间提取出来一些有用的信息。已有理论证明,在Binding和Hiding都很完美的承诺方案是不可能存在的。但是在用来做隐私保护的零知识证明方面,我们通常用第一类承诺,也就它是PerfectHiding,但承诺是ComputationalBinding。因为我们要把承诺上链,上链就意味着100年以后它仍然还被所有人看得见,但不用担心100年以后这个信息真的能被别人破解。另外,这一类的承诺可以产生非常简洁的零知识证明,这就是前面我提到的Argument。zkSNARK原理
比特币盈利地址数量创近9个月新高:金色财经报道,据Glassnode数据显示,比特币盈利地址数量(7d MA)占比达到69.737%,为近9个月以来最高值。[2023/2/5 11:47:42]
凭什么能够做到用100个字节去承诺一个数据库,同时还能去证明这些数据满足一定的性质,这听上去挺不可思议的。
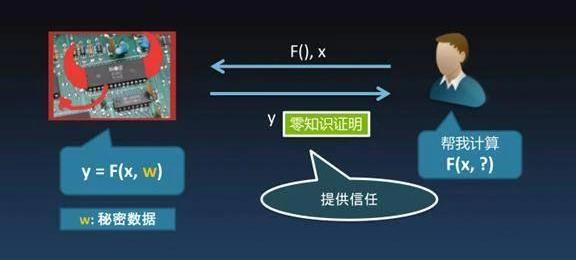
首先再回顾下什么叫「零知识证明」?就是右边Bob说要做一个计算,把计算给远程一台不太相信的机器,这个机器可能已经被黑客控制了或者这个人可能会捣乱,但没关系,把函数给它,输入X,过一会交给我一个Y。虽然不相信那台机器,但因为看见Y了,虽然对Y也是有怀疑的,但因为检查了附加的零知识证明,零知识证明告诉我这个Y是真的,我就相信了。这个怎么做到的呢?先回到一个最朴素的想法,如果有台机器去跑我的程序,我看不见肯定不放心,那最简单的做法就是拿一个摄像机从头到尾把整个计算过程给录制下来,拿到视频之后可以一帧一帧的去检验,是不是计算的每一步都是正确的。这个很傻,但理论上也许可行。但显然方案非常不实用,因为机器在跑的时候,机器的内存状态非常大,比方说4G内存,把整个过程录下来视频文件会超级大,以至于无法验证。有没有办法改进呢?我们采用计算电路的计算模型,而不是CPU加内存的模型。算术电路计算模型和计算机CPU跑程序的表达能力是大致相当的,基本上常见的计算都可以表达。算术电路由一些互相连接的「门」组成,有「乘法门」与「加法门」。输入从电路的左边输入,运算完右边的输出线上产生运行结果,整个过程就是在算「+」、「×」,不要小看这两种运算,它们能表达绝大多数运算。算术电路的好处是它的计算过程是可以拍照的。这个时候只要相机按快门拍一下,把电路的全景拍下来,就相当于记录了所有的计算过程。这样一来,验证计算就不再是验证视频,视频是一帧一帧看的,但是照片就一张照片,只要验证照片的每个细节就可以。怎么验证电路计算呢?要验证每一个门的运算,对于每一个加法门,验证左输入和右输入加起来等不等于输出。对于乘法门,验证左输入和右输入乘起来等不等于输出。只要耐心地挨个检查每一个门,肯定就没问题。如果有上百亿个门,可能验证要花不止一年的时间。有没有一种办法把这么多门的验证过程变的简单?用「多项式编码」这个数学工具可以做到这一点。比如说有一些数:y0、y1、y2,我们把他们放到一个XY轴平面上,变成一个个的点,然后找到一根曲线恰好通过那些点,相当于用一根曲线编码了所有的数值,从y0到yn。编码成曲线有什么好处呢?好处是如果我想改其中某一个值yk,哪怕只要改动一点点,整条曲线就会发生明显的扰动。扰动后的曲线和原曲线只在n个点处相同,而其它的点都产生了偏离。多项式编码之后能放大任何一个哪怕微小的修改。于是我们可以通过随机验证一个点,就能检查曲线编码的点有没有被修改过。接下来可以对刚才算术电路中所有乘法门的左输入门、右输入门、输出门做三个不同的多项式编码,形成三根曲线。现在只要有三根曲线,验证这三根曲线之间满足乘法关系就够了。验证乘法关系只需要随机抽样X轴上的一个点均可,不需要再验证一百亿个门。虽然验证了这三根曲线,但显然验证者看到了太多的秘密,零知识证明要保证计算过程的秘密不被泄漏。怎么做?可以把多项式运算同态映射到椭圆曲线群上。整数有限域的加法运算会映射到椭圆曲线群上的二元运算。整数乘法运算可以同态映射到椭圆曲线群上的双线性配对操作,乘法只能是单乘法,但足可以验证算术电路的运算关系。这个过程看似简单,但zkSNARK的研究是基于许许多多的密码学家的苦苦探索,路线可以追溯到IKO07,2010年Groth有了初步想法,重点的突破是2013年,而Groth16的改进方案是现在业界最流行的零知识证明算法。还有一些非常新改进方案如:Marlin、Aurora、Spartan、Fractal,都是由GGPR13算法不断改进一路发展过来的。2013年的GGPR13论文是比较大的突破,许多美妙的想法都来源于它。论文的四位作者是RosarioGennaro、CraigGentry、BryanParno、MarianaRaylova。
《经济学人》:FTX崩溃将导致Binance面临更严格的审查:11月17日消息,《经济学人》撰文介绍Binance CEO cz,并从FTX崩溃事件切入评价了Binance的发展。文中指出,Binance一直是大量全球金融监管机构调查的目标,包括几乎所有相关的美国监管机构,FTX的崩溃无疑将导致“更严格的审查”。然而,《经济学人》认为,随着加密市场崩盘的恶化,以及监管部门的强力介入,加密市场的“TeflonMan”可能不会永远完好无损。[2022/11/17 13:15:48]
看一下GGPR13/Pinocchio/Groth16框架。当我们想表达任何计算的时候,先用高级语言编写代码,然后通过compiler编译成算术电路,再通过矩阵表示产生R1CS矩阵,并通过多项式编码产生QAP,最后通过Trusted-Setup产生:ProvingKey、VerifyingKey。用ProvingKey可以证明计算过程,而通过VerifyingKey就可以知道证明π是对的。零知识证明+深度神经网络
有了零知识证明之后我们可以为数据库计算承诺并发布到链上,通过Commitment把数据库放到链上后可以做很多很多事情,可以利用数据库产生大量有用的信息,在不暴露个人隐私的情况下能够将信息共享给朋友、企业以及全社会。接下来介绍一下我们团队在深度网络方面做的阶段性成果。图像识别用处很广,这是一个标准的图像设别的模型,标准的测试用例里有飞机、汽车、鸟、狗等,分辨率是224×224。接下来要做隐私保护+机器学习。
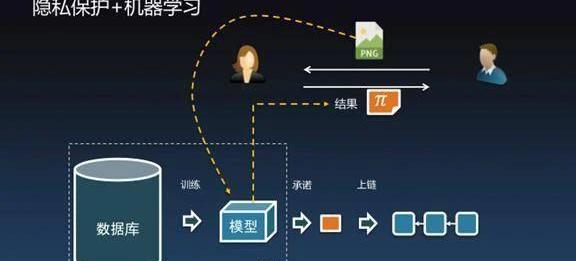
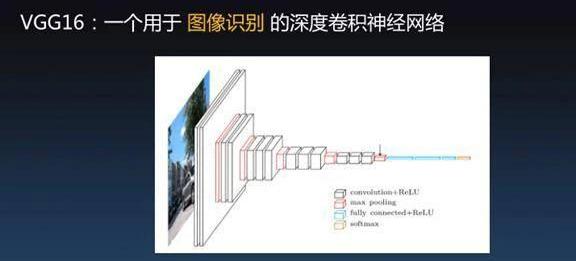
左边有个数据库,数据库里面有很多隐私信息,经过机器学习后产生人工智能模型。Alice不希望暴露模型,毕竟模型里能反映出个人隐私。但Alice觉得模型又可以给Bob提供有价值的信息,Bob就会提供一张图片交给Alice说你来帮我识别一下图片,但是我又不知道你的训练集的细节。Alice就可以拿着图片放到模型里进行识别并产生结果,同时还附带了零知识证明。如果模型产生的结果是识别出了一只猫,但是我还告诉你零知识证明,证明这个结果确实是通过某个秘密模型识别出来的,当然猫狗不需要证明也能看出来,但对于有些机器学习场景是没有办法确定预测结果是否可信的。比如医疗诊断拍一张片子有没有癌症的早期迹象,这个结果没有办法通过看片子看出来,但模型可以告诉你是非常健康的。你不相信没关系,零知识证明可以告诉你这确实是通过非常可靠的X光片数据库推断出来的结果。模型可以承诺上链,使得Alice绝对不可能Bob,关键的是你不再需要信任Alice这个人是好人还是坏人,如果能产生证明结果就是对的,只关心结果,不关心谁提供。接下来做了图像识别的实验,是VGG16的神经网络模型。它是一个16层的深度神经网络。有大量的参数,14个卷积层、2个全连接层、Relu激活函数、Max-pooling池化。
Chamath Palihapitiya:所有资产和财产都将代币化:金色财经报道,亿万富翁Chamath Palihapitiya预测称,人们最终会找到一种方法,将他们所有的资产和财产代币化,将它们放在区块链上,以努力获取价值。此外,根据Palihapitiya的说法,把他们的资产放在链上的用户不会介意交税,因为有可能产生超额的收入。(The Daily Hodl)[2022/10/10 12:51:37]
做这件事情非常有挑战,首先没有任何前人的工作供我们参考。挑战一:如何在算术电路中进行科学计算。科学计算里有大量的小数与浮点数运算。我们选择在有限域上编码定点数,对VGG16模型所有的数据做归一化处理,保证所有的数不超过256。取六位小数定点数,8bit表示整数部分,6bit表示小数部分,用24个bit表示一定点数。用数字电路实现定点数上的各种运算。挑战二:R1CS矩阵巨大无比,需要PB级别内存。一般计算机的内存是GB的,服务器到几百G内存已经算很大了。如果真的把R1CS矩阵算术电路编码出来,需要PB级的内存。正常的机器难以承受。我们算了一下做VGG16图像识别,需要146亿个乘法门。据我们所知,这是世界上首次进行如此大规模的实用算法的零知识证明。乘法数量分布大部分是卷积层,做深度神经网络时大量是卷积运算,占90%以上。电路矩阵太大了,我们不得不发明了一种新的零知识证明方案——CLINK,用来证明图片识别过程。CLINK与其它零知识证明方案相比,采取了一些特殊的技术来处理大规模电路。技术一:巨大电路里有着大量相重复的电路。就图像识别而言,有非常多的卷积层,这么多卷积层的电路部分是相似的,可以把相似的进行合并处理。技术二:巨大电路可以进行拆解,拆成很多小电路,这样内存可以放得下小电路,一个一个做,做完以后再链接起来。电路拆解完但多个电路之间连线的部分需要保护,这些值仍然是秘密,是不能暴露出来的。我们仍然用承诺把中间所有子电路之间暴露出来的连线保护起来。然后就能实现电路的拆解。相同的子电路可以合并证明。最后对巨大电路产生了好多个零知识证明,加上中间值承诺,最后拼成完整的零知识证明。过程中为子电路产生零知识证明,对中间暴露的线计算承诺,中间值不作为公共输入/输入把结果打包再压缩。我们做了两个实验方案:方案一:尽量发挥多核CPU的优势,同时并行计算VGG16,所有16层的电路一起并行证明,所有承诺层之间的链接证明是同时做的。方案二:串行一层一层来,先做第一层第二层,再做第一层和第二层之间的链接证明。这里非常感谢QTUM团队给我们提供了超级服务器,配备有1TB内存,高性能的SSD。我们先用第一个并行方案,因为并行方案仍然需要很大的内存,虽然不需要PB级,但跑完并行方案大概花了5TB的内存,其中4TB是跑交换分区上。因为整个过程使用到了SSD交换分区,所以性能会受到很大的影响。并行方案:证明图片识别224×224分辨率的小猫,证明时间要花25个小时。如果给一台4TB内存的机器,可能只需要花5小时,但4TB内存的机器很难找,而验证时间要花1个小时。证明长度在80KB,内存占用峰值是5TB。串行方案:看起来慢一些,但在机器上跑速度反而更快,因此只用到了500GB内存,没有用到交换分区,所以整体上更快一点,证明时间为20小时,验证时间在1小时,证明长度110KB。在我们做实验的过程中,韩国的学者也发了一篇论文草稿,在和我们做很类似的工作。最大的不同是他们对VGG16进行了一些妥协性修改,特别是在电路里做Maxpooling的时候非常困难,于是改用平均值的方式做pooling。他们当中引入了非常大的83GB的CRS。在我们的方案里CRS非常小,实用性更好。这是我们所能知道的国际上的最新研究成果。大数据零知识证明的应用前景
Curve上stETH与ETH兑换比例跌至1:0.9367,倾斜程度有所缓和:金色财经报道,据Curve页面显示,stETH与ETH兑换比例跌至1:0.9367。当前池内拥有114,804.22枚ETH(18.44%),507,649.03枚stETH(81.56%),流动性池比例倾斜程度有所缓和。[2022/6/20 4:40:27]
零知识证明已经从理论走向工程,正逐步走向应用,未来将可以处理更大量的数据。我们在探索过程中研究出的CLINK算法,可以支持大数据的统计、查询、以及其它复杂的操作,甚至包括深度神经网络的推断过程。未来这些技术都可以用在:1、可验证数据库。每个人可以把数据放在数据库里,但从来不需要把数据库告诉任何人。当别人跟你要数据的时候都可以把数据做一定的处理,但可以证明对处理并没有造假,同时保证数据真的有价值。可验证数据库是未来让互联网公司通过非常安全的手段共享数据,提供了新的技术方向。2、可验证的隐私保护技术。个人数据比如说健康数据、出行记录需要通过加噪音来保护隐私,再交给第三方的互联网公司,通过机器学习给我们提供更好的服务。但又保证数据的可用性与真实性。在个人隐私得到充分保护的情况下给商业公司共享更好的数据,让他们反过来为我们提供更好的服务,是未来数字经济的商业模式。如果大家对零知识证明、人工智能、机器学习感兴趣的话可以与我们线下讨论交流,谢谢大家。
编者按:本文来自金色财经,Odaily星球日报经授权转载。在为WBTC流动性池引入UNI代币收益耕作激励措施之后,以太坊上的代币化比特币——WBTC供应量正在大幅增长.
1900/1/1 0:00:00编者按:本文来自以太坊爱好者,作者:TimDaubenschütz,翻译&校对:闵敏&阿剑,Odaily星球日报经授权转载。很久以前,我曾面对满座听众介绍BigchainDB.
1900/1/1 0:00:00编者按:本文来自彩云区块链,Odaily星球日报经授权转载。近期uniswap和MEME的空投引爆了整个币圈的注意力,很多人defi亏损一塌糊涂,结果最后靠uniswap空投回本了,更多的没领到.
1900/1/1 0:00:00文|Nancy编辑|Tong出品|PANewsDeFi充满戏剧性色彩。过去数月的DeFi浪潮中,百倍、千倍的耕种收益随处可见,“农民们”纷纷开启没日没夜的“抢种抢收”模式,市场中靠DeFi发家致.
1900/1/1 0:00:00编者按:本文来自巴比特资讯,作者:方沁雨,星球日报经授权发布。今天币圈的热点属于Uniswap,毫无争议.
1900/1/1 0:00:00Odaily星球日报译者|Moni 根据Coingecko一项最新调研结果显示,收益耕作农民大多依赖于审计来监督他们加入项目的安全性,但许多人其实看不懂DeFi智能合约.
1900/1/1 0:00:00