隐私保护方案的工程实现,如何关联到学术论文中天书一般的公式符号?密码学工程中,有哪些特有的数据编解码方式、存在哪些认知误区和注意事项、需要克服哪些限制和挑战?
作为支撑隐私保护方案的核心技术,如何运用数据编解码,将密码学论文中抽象的数学符号和公式具象成业务中具体的隐私数据,是学术成果向产业转化需要跨过的第一道门槛。
学术论文中所使用的数学语言与工程中所使用的代码编程语言,差异非常大。不少在数学上容易定义的属性和过程,若要在工程上提供有效实现,颇具挑战。实现不当的话,甚至可能破坏学术方案中的安全假设,最终导致方案失效、隐私数据泄露。
常用的密码学算法拥有多种标准化编解码方式,其应用到隐私保护方案,可以分别解决相应问题。以下将逐一展开。
业务应用难题:类型不匹配
工程实现之道:数据映射
在实际业务中,隐私数据可以表现为五花八门的数据类型,这些类型通常不满足密码学协议中特定的类型要求,无法被直接使用,这就是我们需要解决的第一个问题:数据类型不匹配。
例如,业务系统中,交易的金额是一个长整型整数,而常见的密码学算法可能要求输入为有限循环群中的一个元素,如果直接使用长整型整数的值,可能该值并不在对应的有限循环群中;在椭圆曲线系统中,单个数值还需要转化成曲线上的点坐标,需要将一个数值转化成两个数值的坐标形式。
林煌博士:轻模式的隐私应用是密码学技术在隐私保护实践中很重要的一步:在今日的《金色深核》线上直播中,针对“假设我们要解决多公司之间数据需要保密且共同使用的问题,三个技术路线如何去做?去年Maskbook火了一下,各位如何看待这种“轻模式”的隐私应用?”Suterusu林煌博士表示关于多个公司之间进行保密数据的安全计算,这个需要结合零知识证明和安全多方计算才能解决。如果我们考虑一种简单的情况,只有两方进行安全计算,一方可以将自己的数据用门限同态加密方案的公钥加密后传输给另一方,另一方依据加密自己的数据生成密文,然后在两个密文上做预定的同态运算,最后双方合作把完成同态操作的密文解密。零知识证明可用于保证这个过程的计算可靠性(computational integrity),比如如何保证生成的加密密文确实是按照正确加密步骤生成的密文且加秘方知道原始明文呢?我们可以使用零知识证明算法针对加密电路生成能够验证明文和密文之间符合加密电路逻辑的证明。轻模式的隐私应用毫无疑问是密码学技术在隐私保护实践中很重要的一步,但这个领域还有很多可以做的事情。[2020/3/11]
针对以上问题,密码学工程实现中,一般通过数据映射进行类型转换处理。具体而言,是将用户的隐私数据,通过一定的方法,变换到具体密码协议要求的数据类型。
下面以密码学中的椭圆曲线(Elliptic Curve)加解密为例,介绍一种常见的数据映射方式。
动态 | 量子链开发者在密码学IACR电子期刊公布幻影隐私协议:金色财经报道,2月13日,量子链开发者在密码学IACR电子期刊公布了基于智能合约的幻影隐私协议(Qtum Phantom Protocol),推动数字资产隐私领域发展。据介绍,幻影隐私协议基于zk-SNARK技术,对Merkle树、hash算法等多个环节进行了改进,使得协议能够高效地运行于智能合约上。量子链幻影隐私协议在智能合约的基础上,实现隐私资产的发行和管理。相比AZTEC只能实现交易金额的隐私,无法隐藏交易地址。幻影协议实现了更彻底的隐私,可以同时隐藏交易金额和交易地址。该协议同时提供隐私资产和公开资产之间的互转功能。据悉幻影隐私协议将率先在Qtum网络部署,同时也计划支持其他的智能合约网络。[2020/2/14]
椭圆曲线可以简单理解为定义了一个特定点的集合,例如下面这种公式定义了比较常见的一类椭圆曲线:
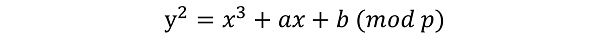
其中满足公式成立的点(x, y)都在椭圆曲线上。椭圆曲线密码通过在限定的点集上定义相关的点运算,实现加解密功能。
在椭圆曲线加解密过程中,首先面临的问题是『如何将待加密的数据嵌入到椭圆曲线上,通过点运算来完成加密操作』。这需要将明文数据m映射到椭圆曲线上的一个特定点M(x, y)。
声音 | “现代密码学之父”迪菲:量子计算不会威胁到区块链:据澎湃消息,3月27日,被誉为“现代密码学之父”的图灵奖得主惠特菲尔德?迪菲(Whitfield Diffie)在博鳌亚洲论坛上接受澎湃新闻采访时表示,量子计算只会威胁到密码学中非常窄、但非常重要的一个领域,上世纪70年代建立起来的公钥加密体系会变得脆弱。但密码学中的许多技术,包括区块链用到的哈希编码在量子计算面前并不脆弱。[2019/3/27]
数据编码方式是将明文数据m通过进制转换到椭圆曲线上某点的x坐标值,然后计算m^3 + am + b的完全平方数,得到y,这样就将m转换到了点M(x, y)。
数据解码方式比较直白,解密还原出明文数据点M之后,读取M的x坐标值,再通过进制转换还原为明文信息m。
然而,密码椭圆曲线是定义在有限域上的,即曲线上是一个离散的点集合。这样会导致计算完全平方数不一定存在,即x没有对应的y在椭圆曲线上,那么,部分明文数据无法转换到椭圆曲线上的点,从而导致部分数据无法被直接加密。

在实际工程化的方案中,为了保证椭圆曲线加解密的可用性,会加入其它更复杂的扩充编码机制,以应对明文数据转换失败的情况。
动态 | Seele元一密码学黄皮书正式公开:今日,Seele元一全球首发的密码学领域黄皮书“多重椭圆曲线的数字签名方法”已被提交至全球预印本资料库资料库资料库arxiv.org发表,并随后于Seele元一官网Seele.pro全文公开。该黄皮书通过椭圆曲线数量和六个参数的动态调整,实现了适用于不同应用场景和安全需求的动态签名机制。Seele元一首席科学家毕伟博士表示:“新签名算法和独特的运行机制,为主网上线提供了更加坚实的安全技术保障。[2018/8/10]
一般而言,密码学协议中所定义的类型要求越多,数据映射的工程实现也会越复杂,如果缺乏高效的数据编解码算法和配套的硬件优化支持,即便密码学协议的理论计算复杂度再低,最终也是难以实用化。
具体的数据映射涉及到很多流程细节和算法参数,一旦存在微小的差异,由不匹配的编码算法所产生的数据,都会极大概率无法解码,导致隐私数据丢失、业务中断。
所以,在具体工程实现时,数据映射需要严格按照已有工程标准的实现要求,以国密SM2为例,可以参考GM/T0009-2012《SM2密码算法使用规范》、GM/T0010-2012《SM2密码算法加密签名消息语法规范》等一系列相关技术标准。
业务应用难题:数据太长
工程实现之道:数据分组
除了类型不匹配,密码学协议中使用的核心算法对输入的数据长度往往也有一定要求。但在实际应用中,需要处理源自不同业务需求的隐私数据,难以限定其长度,难免会出现数据长度超出核心算法处理长度的情况。
密码学专家:闪电网络主链beta测试版只是实验的开端:15日闪电网络实验室正式上线了主链的测试beta版本,自称是“重要里程碑”,然而美国约翰霍普金斯大学的密码学专家马修?格林(Matthew Green)今日在发推称,“很多人把闪电网络beta测试版当作是一个成功的结果,但其实这只是一个苦难重重的实验的开端”。闪电网络实验室近日宣布获得250万美元种子轮融资。[2018/3/17]
例如,对称加密AES算法AES-128、AES-256,表明其使用的密钥位数分别是128位和256位,但加密过程中单次进行核心密码运算时处理的数据固定为128位。
针对以上问题,密码学工程实现中一般通过数据分组进行处理,即化整为零,将长数据切分为多个较短且符合长度要求的数据块。
典型的例子是分组加密,例如AES、DES等。分组加密顾名思义就是,将输入的数据分组为固定长度的数据块,然后以数据块为单位作为核心密码算法的处理单元进行加解密处理。
为了在数据分组之后,依旧保持方案的安全性,数据分组技术不仅仅是简单地对数据进行划分,还需要引入额外的流程操作。
下面以AES 256位密钥加密为例,介绍其中典型的分组加密模式ECB、CBC和CTR。
ECB模式 (Electronic Code Book)
ECB是最简单的分组加密模式,也是不安全分组模式的典范。
假定有1280位待加密的数据,ECB模式将其平均分为10个128位数据块。每个数据块使用相同的密钥单独加密生成块密文,最后块密文进行串联生成最终的密文。

ECB模式的加密特点是在相同的明文和密钥情况下,其密文相同,因此泄露了明文数据与密文数据之间的关联性,不推荐用于任何隐私保护方案中。
CBC模式 (Cipher Block Chaining)
CBC模式通过前后数据块的数据串连避免ECB模式的缺点。
与ECB模式类似,CBC模式中,每个明文块先与前一个密文块进行异或后,再进行加密。在这种方法中,每个密文块都依赖于它前面的所有明文块。同时,为了保证每个数据密文的随机性,在第一个块中需要使用一个随机的数据块作为初始化向量IV。
CBC模式解决了ECB模式的安全问题,但也带来了一定的性能问题。其主要缺点在于每个密文块都依赖于前面的所有明文块,导致加密过程是串行的,无法并行化。
CTR模式 (CounTeR)
CTR模式的出现让分组加密更安全且并行化,通过递增一个加密计数器以产生连续的密钥流,使得分组密码变为流密码进行加密处理,安全性更高。
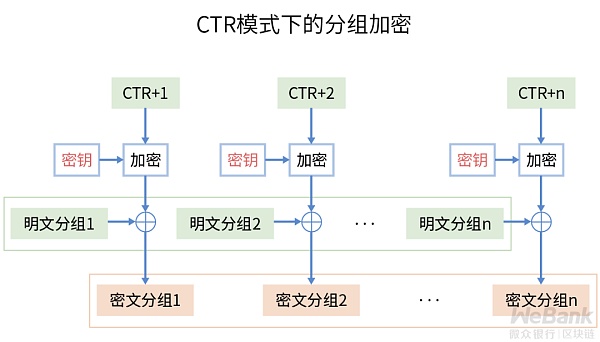
CTR加密和解密过程均可以进行并行处理,使得在多处理器的硬件上实现高性能的海量隐私数据的并发处理成为了可能,这是目前最为推荐的数据分组模式。
密码学协议中的数据分组与传统大数据处理中的数据分组有很大区别。理想情况下,数据分组不应该弱化隐私保护的强度,不能为攻击者获取未授权的信息提供可乘之机。这往往会涉及精心的数据分组方案设计,不能简单看作是数据分块之后的批处理。
业务应用难题:数据太短
工程实现之道:数据填充
数据太长是个问题,数据太短往往也是问题。
在以上分组处理的过程中,最后一个数据块中数据长度不足,密码学协议中的核心算法也可能无法工作。
假定一个密码协议处理的数据块长度要求为6字节,待加密的隐私数据长度为7字节。用两个十六进制数代表一个字节数据,其示例如下:
b1 b2 b3 b4 b5 b6 b7
7字节长于数据块的处理长度6字节,因此该数据将被分组,且可以分为两个数据块。分组示例如下:
第一个数据块:b1 b2 b3 b4 b5 b6
第二个数据块:b7
其中第一个数据块刚好是6个字符,第二个数据块只有1个字节,这个数据块就太短了,不满足处理要求。
针对以上问题,密码学工程实现中一般通过数据填充进行处理,即将短的数据块填充补位到要求的字节长度。示例中第二个数据块需要进行数据填充,为其补上缺少的5个字节。
与数据分组类似,这里的数据填充也不是普通的数据填充,也应该满足一定的安全性要求。最常用的数据填充标准是PKCS#7,也是OpenSSL协议默认采用的数据填充模式。
PKCS#7填充
需要填充的部分都记录填充的总字节数。应用于示例中第二个数据块,则补5个字节都是5的数据,其填充效果如下:
b7 05 05 05 05 05
这里还存在一个问题:如果一个隐私数据的最后一个分组,刚好就是一个符合其填充规则的数据,在事后提取原始数据时,如何分辨是原始数据还是填充之后的数据?
避开这种歧义情况的关键是,任何长度的原始数据,在最后一个数据块中,都要求进行数据填充。

值得注意的是,对隐私数据加密时,按特定填充模式进行处理,那么填充的数据也将被加密,成为加密前明文数据的一部分。解密时,其填充模式也需要和加密时的填充模式相同,这样才可以正确地剔除填充数据,提取出正确的隐私数据。
在隐私保护方案的编解码过程中,以上提到的数据映射、数据分组、数据填充,都是保证隐私数据安全的必要环节。此外,在特定的合规要求下,实际业务系统还需要引入更多的相关数据预处理环节,如数据脱敏、数据认证等,使得数据在进入密码学协议前,尽早降低潜在的隐私风险。
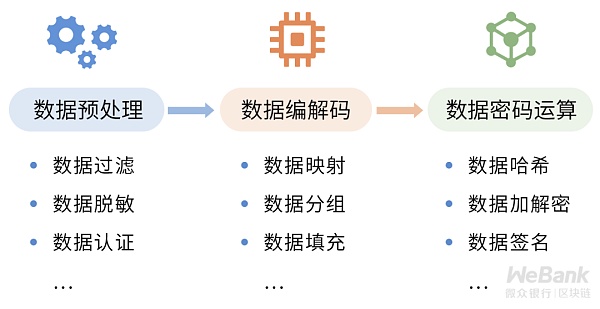
正是:理论公式抽象赛天书,工程编码巧手点迷津!
学术论文的公式符号与隐私保护方案的可用工程实现之间,存在一条不小的技术鸿沟,而密码学特有的数据编解码,正是我们建立桥梁实现学术成果产业转化的基石。
安全高效的数据编解码技术,对于处理以5G、物联网为爆点的海量隐私数据应用意义重大,是隐私数据进出业务系统的第一道防线,其重要性不亚于其他密码学原语。
了解完数据编解码之后,接下来将进入具体应用相关的密码学原语,欲知详情,敬请关注下文分解。
市值最高的加密货币比特币在北京时间5月12日迎来了诞生来第三次区块奖励减半,如今已过两周,《比推》对比了减半时与现在的一些数据的变化。 哈希率方面的变化最为明显.
1900/1/1 0:00:002017年12月3日,Telegram Open Network(TON)发布了长达132页的白皮书。891天后,2020年5月12日,Telegram宣布中止TON区块链项目.
1900/1/1 0:00:00本期将继续为大家带来polkadot创世神林嘉文博士(Dr.Gavin Wood)关于如何推进波卡主网上线的讲解.
1900/1/1 0:00:00大方向周线级别,上周收盘价格已突破14000-10500的下降趋势线,后面回踩不破继续向上的概率大,周线MACD多头量柱0轴上方持续增长,价格沿周线MA5均线持续上行.
1900/1/1 0:00:00随着央行数字货币已经拉弓上膛,数字资产和央行数字货币DCEP的结合的讨论增多了。但究竟如何结合,腾讯近期公开的一些专利,解开了部分面纱.
1900/1/1 0:00:00据Decrypt5月4日报道,以太坊的矿工们在短短5年时间里总共挖出了1000万个区块,比比特币多了27万个区块.
1900/1/1 0:00:00