许振文
腾讯游戏
增值服务部后台开发组组长
从事游戏大数据相关领域8年多,负责游戏数据分析平台iData的架构设计和关键模块开发,为腾讯超过400款游戏提供高效快速的数据分析服务。
中国通信研究院发布的微服务行业标准和分布式消息队列技术标准的核心制定者之一,Linux内核之旅开源社区的负责人,Istio社区Member。
在分布式存储,调度、多维数据分析、实时计算、事件驱动决策系统、微服务、ServiceMesh领域有丰富的实战经验。
大家好我是许振文,今天分享的主题是《基于Flink+ServiceMesh的腾讯游戏大数据服务应用实践》,主要会分为以下四个部分进行分享:
背景和解决框架介绍
实时大数据计算OneData
数据接口服务OneFun
微服务化&ServiceMesh
一、背景和解决框架介绍
1、离线数据运营和实时数据运营

首先介绍下背景,我们做游戏数据运营的时间是比较久的了,在13年的时候就已经在做游戏离线数据分析,并且能把数据运用到游戏的运营活动中去。
但那时候的数据有一个缺陷,就是大部分都是离线数据,比如今天产生的数据我们算完后,第二天才会把这个数据推到线上。所以数据的实时性,和对游戏用户的实时干预、实时运营效果就会非常不好。尤其是比如我今天中的奖,明天才能拿到礼包,这点是玩家很不爽的。
现在提倡的是:“我看到的就是我想要的”或者“我想要的我立马就要”,所以我们从16年开始,整个游戏数据逐渐从离线运营转到实时运营,但同时我们在做的过程中,离线数据肯定少不了,因为离线的一些计算、累计值、数据校准都是非常有价值的。
实时方面主要是补足我们对游戏运营的体验,比如说在游戏里玩完一局或者做完一个任务后,立马就能得到相应的奖励,或者下一步的玩法指引。对用户来说,这种及时的刺激和干预,对于他们玩游戏的体验会更好。
其实不单单是游戏,其他方面也是一样的,所以我们在做这套系统的时候,就是离线+实时结合着用,但主要还是往实时方面去靠拢,未来大数据的方向也是,尽量会往实时方向去走。
2、应用场景
1)游戏内任务系统
这个场景给大家介绍一下,是游戏内的任务系统,大家都应该看过。比如第一个是吃鸡里的,每日完成几局?分享没有?还有其他一些活动都会做简历,但这种简历我们现在都是实时的,尤其是需要全盘计算或者分享到其他社区里的。以前我们在做数据运营的时候,都是任务做完回去计算,第二天才会发到奖励,而现在所有任务都可以做到实时干预。
游戏的任务系统是游戏中特别重要的环节,大家不要认为任务系统就是让大家完成任务,收大家钱,其实任务系统给了玩家很好的指引,让玩家在游戏中可以得到更好的游戏体验。
2)实时排行版
还有一个很重要的应用场景就是游戏内的排行榜,比如说王者荣耀里要上星耀、王者,其实都是用排行榜的方式。但我们这个排行榜可能会更具体一些,比如说是今天的战力排行榜,或者今天的对局排行榜,这些都是全局计算的实时排行榜。而且我们有快照的功能,比如0点00分的时候有一个快照,就能立马给快照里的玩家发奖励。
这些是实时计算的典型应用案例,一个任务系统一个排行榜,其他的我们后面还会慢慢介绍。
3、游戏对数据的需求
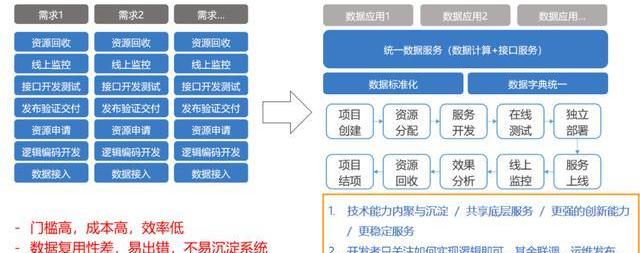
再说一下为什么会有这样一个平台,其实我们最初在做数据运营的时候,是筒仓式或者手工作坊式的开发。当接到一个需求后,我们会做一个资源的评审、数据接入、大数据的编码,编码和数据开发完后,还要做线上资源的申请、发布、验证,再去开发大数据计算完成后的服务接口,然后再开发页面和线上的系统,这些都完了后再发到线上去,做线上监控,最后会有一个资源回收。
Cosmos Hub社区提议提前聘请律师,以应对潜在监管影响:6月17日消息,在美国SEC起诉币安、Coinbase之后,Cosmos Hub社区已起草有关聘请律师的提案,作为潜在的预防措施。此举至少在一定程度上是由于SEC将Cosmos Hub原生代币ATOM归类为证券。
在提案草案中,Cosmos Hub社区成员RoboMcGobo指出,币安诉讼中的指控可能会产生更严重、更广泛的后果。如果币安诉讼中的任何指控需要法院确定ATOM是一种证券的门槛,那么法院的决定可能会对Cosmos Hub产生深远的影响,当然也会对ATOM代币产生深远的影响。如果这种先例成为现实,Cosmos Hub将没有太多机会为自己辩护。因此,社区成员的想法是,Cosmos Hub应该考虑聘请能够在最坏情况下提供法律建议的律师或律师事务所。
不过,有人担心聘请律师可能会带来中心化和监管方面的问题。该提案目前处于草案阶段,尚未提交社区投票。(Blockworks)[2023/6/17 21:43:59]
其实这种方式在很早期的时候是没有问题的,那为什么说现在不适应了?主要还是流程太长了。我们现在对游戏运营的要求非常高,比如说我们会接入数据挖掘的能力,大数据实时计算完成之后,我们还要把实时的用户画像,离线画像进行综合,接着推荐给他这个人适合哪些任务,然后指引去完成。
这种情况下,原来的做法门槛就比较高了,每一个都要单独去做,而且成本高效率低,在数据的复用性上也比较差,容易出错,而且没有办法沉淀。每一个做完之后代码回收就扔到一块,最多下次做的时候,想起来我有这个代码了可以稍微借鉴一下,但这种借鉴基本上也都是一种手工的方式。
所以我们希望能有一个平台化的方式,从项目的创建、资源分配、服务开发、在线测试、独立部署、服务上线、线上监控、效果分析、资源回收、项目结项整个综合成一站式的服务。
其实这块我们是借鉴DevOps的思路,就是你的开发和运营应该是一个人就可以独立完成的,有这样一个系统能够去支撑这件事。当一个服务在平台上呈现出来的时候,有可能会复用到计算的数据,比说实时的登录次数或击杀数,那这个指标在后面的服务中就可以共用。
而且有了这样一个平台之后,开发者只需主要关注他的开发逻辑就行了,其余两条运维发布和线上运营都由平台来保证。所以我们希望有一个平台化的方式,把数据计算和接口服务统一起来,通过数据的标准化和数据字典的统一,能够形成上面不同的数据应用,这个是我们的第一个目标。
其实我们现在都是这种方式了,第一是要在DevOps的指导思想下去做,尤其是腾讯去做的时候数据服务的量是非常大的,比如我们去年一共做了5、6万的营销服务,在这种情况下如果没有平台支撑,没有平台去治理和管理这些服务,单靠人的话成本非常大。
4、思路
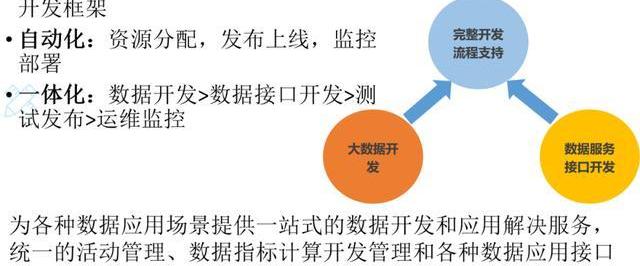
3个现代化,大数据应用的DevOps。
我们的思路也是这样,三个现代化,而且把大数据应用的DevOps思路实现起来。
规范化:流程规范、数据开发规范和开发框架;
自动化:资源分配、发布上线、监控部署;
一体化:数据开发、数据接口开发、测试发布、运维监控。
所以我们针对大数据的应用系统,会把它拆成这样三块,一个是大数据的开发,另外一个是数据服务接口的开发,当然接口后面就是一些页面和客户端,这些完了后这些开发还要有一个完整的开发流程支持。
这样我们就能够为各种数据应用场景提供一站式的数据开发及应用解决服务、统一的活动管理、数据指标计算开发管理和各种数据应用接口自动化生产管理的一站式的服务。
这样的系统能保障这些的事情,而且我们这里也合理拆分,不要把大数据和接口混到一块去,一定要做解耦,这是一个非常关键的地方。
5、数据服务平台整体架构
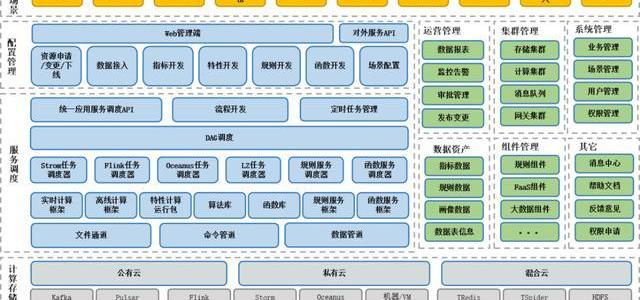
1)计算存储
这个框架大家可以看一下,我认为可以借鉴,如果你内部要去做一个数据服务平台的话,基本上思路也是这样的,底层的Iass可以不用管,直接用腾讯云或者阿里云或者其他云上的服务就可以了。
我们主要是做上层这一块的东西,最下面的计算存储这个部分我们内部在做系统的时候也不是care的,这块最好是能承包出去。现在Iass发展到这个程度,这些东西在云上可以直接像MySQL数据库或者Redis数据库一样购买就行了,比如Kafka、Pulsar、Flink、Storm。
律师:Taylor Swift出于“未注册证券”担忧,最终未与FTX签署1亿美元赞助协议:4月19日消息,著名歌手泰勒·斯威夫特(Taylor Swift)此前退出了FTX 1亿美元的代言赞助协议。起诉其他名人推广FTX的律师称,她是唯一一个询问未注册证券相关事宜的人士。
据悉,一份最新提交的法庭动议显示,涉及推广FTX的集体诉讼的相关名人要求法院驳回此案,这些名人包括喜剧演员兼导演拉里·大卫(Larry David)、NFL球星汤姆·布雷迪(Tom Brady)、吉赛尔·邦辰(Gisele Bundchen)、NBA球星斯蒂芬·库里(Stephen Curry)、乌多尼斯·哈斯勒姆(Udonis Haslem)、特雷弗·劳伦斯(Trevor Lawrence)、凯文·奥利里(Kevin O’Leary)、棒球明星大谷翔平(Shohei Ohtani)、大卫·奥尔蒂斯(David Ortiz)、网球明星大坂直美(Naomi Osaka)以及NBA金州勇士队。[2023/4/19 14:13:57]
存储这块我们内部的有TRedis、TSpider,其实就是Redis和MySQL的升级版本。基础这块我建议大家如果自己构建的话,也不需要太过于关注。
2)服务调度
系统核心主要是在中间的服务调度这个部分,它是统一的调度API,就是上层的一些服务能发下来,然后去统一调度。另外一个就是流程的开发,我们有一个不可缺少的调度系统,这里我们使用的是DAG调度引擎,这样我们可以把离线任务、实时任务、实时+离线、离线+函数接口的服务能够组合起来,来完成更复杂实时数据应用场景。
比如我们现在做的实时排行榜,把实时计算任务下发到Flink后,同时会给Flink下发一个URL,Flink拿到URL后,它会把符合条件的数据都发送到URL,这个URL其实就是函数服务,这些函数服务把数据,在Redis里做排序,最终生成一个排行榜。
再往下的这个调度器,你可以不断地去横向拓展,比如我可以做Storm的调度器、Flink的调度器、Spark的调度器等等一系列。在这块可以形成自己算法库,这个算法库可以根据场景去做,比如有些是Flink的SQL的分装,也就是把SQL传进来,它就能够计算和封装的Jar包。另外比如一些简单的数据出发、规则判断也可以去做,直接把算法库分装到这块就行。
其实这块和业务场景没有直接关系的,但算法库一定是和场景是有关系的,另外下层我们会有写文件通道,比如说一些jar包的分发,这里腾讯用的是COS,能够去做一些数据的传输和Jar包的提交。
还有一个命令管道,它主要针对机器,比如提交Flink任务的时候一定是通过命令管道,然后在一台机器去把Jar包拉下来,然后同时把任务提交到Flink集群里去。数据管道也是类似的一个作用。
3)各种管理
另外还要将一个蛮重要的内容,右边绿色这块的运营监控、集群管理、系统管理,还有消息中心、帮助文档,这些都是配套的,整个系统不可缺少的。
还有一部分是组件管理,包括大数据组件管理、函数管理、服务的二进制管理都可以在这里能够做统一的管理。
数据资产,比如我们通过Flink或者Storm能够生成的数据指标,它的计算逻辑的管理都在这里面,包括我们计算出来后,把这些指标打上标签或者划后,我们也作为数据资产。
还有一个最重要的是数据表的管理,我们无论是Flink或Storm,它的计算最终的落地点一定是通过一个数据表能算出来的。其他都还好,数据报表,比如每天计算多少数据,成功计算多少,每天有多少任务在跑,新增多少任务,这些都在里面可以做,包括我们版本的发布变更。
还有一个是外部管理端,这个根据业务场景去做就行了,等会演示我们管理端的时候大家就可以看到,其实我们的菜单相对来说比较简单,根据比如我们的数据接入,从源头把数据接入到Kafka或者Pulsar里去。然后数据指标基于接入的数据表,进行数据指标的计算,比如一些特性的Jar包,它是多张表的数据混合计算,或者是加上的表的混合计算,等等一系列通过硬场景做的一些分装。
我们最终把这些做完后,所有的大数据都是通过对外的服务API暴露出去的,比如最终游戏任务是否完成,用户ID过来后我们能看这个用户的任务是否完成,这样的一些应用场景可以直接使用API去操作。
这是整个流程,讲得比较细后面大家才会更清晰。
二、实时大数据计算OneData
1、数据开发流程
苏富比启动Natively Digital:Relics II NFT拍卖活动:12月17日消息,苏富比宣布启动Natively Digital:Relics II NFT拍卖活动,本次拍卖总计有15个NFT,参与拍卖的NFT系列包括Carnaby Street(1枚)、Speak on Liberty#1(1枚)Chimpers(8枚)、以及“隐形人”Invisible Friends(5枚),竞标价格范围为2500-75000美元,拍卖活动将于12月21日结束。[2022/12/17 21:50:30]
这是我们整体的数据应用流程:
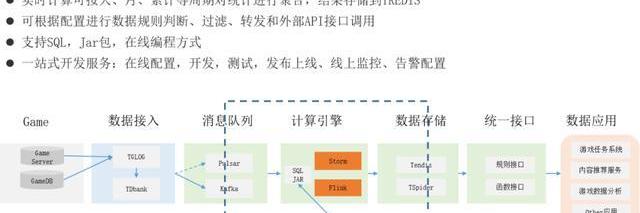
我们的GameServer先把数据上传到日志Server,日志Server再把数据转到Kafka或者Pulsar,就是消息队列里。
接进来后是数据表,数据表是描述,基于描述的表去开发指标、数据。比如我们这里一共有三类,一类是SQL,另外一类是我们已经分装好的框架,你可以自己去填充它的个性代码,然后就可以在线完成Flink程序的编写。
还有一种是自己全新的在本地把代码写好,再发到系统里去调测。之前说了在大数据计算和数据接口一定要做解耦,我们解耦的方式是存储,存储我们用Redis。它这种做法是把Redis和SSD盘能够结合起来,然后再加上RockDB,就是Redis里面它hold热点数据,同时它把这些数据都通过这个RockDB落地到SSD盘里去,所以它的读写性非常好,就是把整个磁盘作为数据库存储,而不像普通的Redis一样再大数据情况下智能把内存作为存储对象。
在大数据把数据计算存储进去后,后面的就简单了,我们提供查询的服务有两种,一种是计算的指标,点一下就可以生成接口,我们叫规则接口;然后我们另外一种,也提供特性化的存储到介质里,我可以自己去定义他的SQL或者查询方式,然后在数据进行加工处理,生成接口。
还有一种方式,是我们在Flink和Storm直接把数据配置我们这边的一个函数接口,比如我刚才讲的排行榜的方式,就给一个接口,他直接在Flink这边处理完成之后,把数据吐到函数接口里面,函数接口对这个数据进行二次处理。
这个是整个处理方式,所以我们前面讲的就是,基于Flink和Storm构建一个全面的、托管的、可配置化的大数据处理服务。主要消费的是Kafka的数据,Pulsar现在在少量的使用。
这样做就是我们把数据的开发门槛降低,不需要很多人懂Flink或者Storm,他只要会SQL或者一些简单的逻辑函数编写,那就可以去完成大数据的开发。
2、数据计算统一
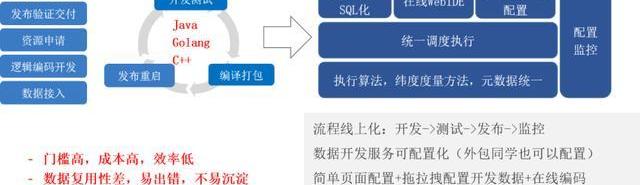
其实我们之前在做的时候,有一些优化的过程,原来每一个计算任务都是用Jar包去写,写完之后就是编辑、打包、开发、发布。后来我们划分了三种场景,一种是SQL化,就是一些我们能用SQL表示的我们就尽量分装成SQL,然后有一个Jar包能去执行这个提交的SQL就可以了。
还有一种是在线的WebIDE,是处理函数的逻辑,举例子Storm里可以把blot和spout暴露出来,你把这两函数写完后,再把并行度提交就可以运行。但这里我们具体实现的时候是基于Flink去做的。
另一个是场景化的配置,我们个性化的Jar包能够统一调度,根据调度逻辑去执行。
3、数据计算服务体系
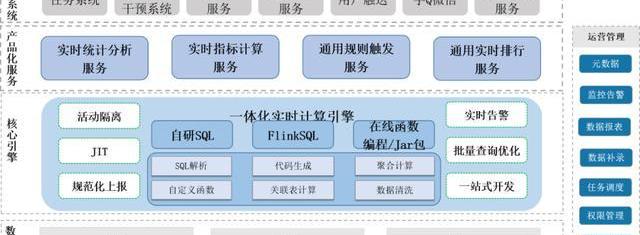
这是我们整个OneData计算体系的过程,支持三种,一种的自研的SQL,一种是FlinkSQL,还有是Jar包。
我们自研的SQL是怎么存储,最早是使用Storm,但StromSQL的效率非常低,所以我们根据SQLParser做的SQL的分装,我们对SQL自己进行解析,自己形成函数,在SQL提交之后,我们用这样的方式直接把它编译成Java的字节码,再把字节码扔到Strom里去计算。
Flink这块我们也继承了这种方式,后面会讲一下两种方式有什么区别。其实我们自研SQL在灵活性上比FlinkSQL要好一点。
这里是做平台化,不能说直接放一个FlinkSQL去跑,因为我们想要在里面统计整个业务逻辑的执行情况,比如SQL处理的数据量,正确的和错误的,包括一些衰减,都是要做统计。
哈萨克斯坦交易所Intebix为未列入制裁名单的俄罗斯公民提供服务:10月20日消息,尽管西方最近对俄罗斯实施制裁,但一些加密货币交易所仍继续为俄罗斯公民提供服务,但也有某些限制条件。
哈萨克斯坦交易所Intebix联合创始人兼首席执行官Talgat Dossanov称,Intebix不仅限于哈萨克斯坦公民使用,其交易所愿意为来哈萨克斯坦的外国人提供服务。他强调,Intebix的加密交易只有欧亚银行(Eurasian Bank)等哈萨克斯坦银行的持卡人才能使用。
Dossanov指出,Intebix只支持经过验证的客户进行加密交易,而当地银行则仔细检查每个潜在客户是否受到制裁。Intebix欢迎未列入制裁名单的俄罗斯公民,但他们需要通过深入的合规检查,并在欧亚银行开立账户,才能执行加密货币到法定货币的交易。(Cointelegraph)[2022/10/20 16:32:30]
这是基本的过程,完了后我们在上面形成的一些基本场景,比如实时统计的场景,PV,UV,用独立的Jar包去算就行了,配置一下表就可以去计算。另外实时指标的服务,比如杀人书,金币的积累数,游戏的场次,王者荣耀里下路走的次数,这种数据都可以作为实时指标。
还有一种是规则触发服务,表里的某个数据满足什么条件时,触发一个接口。还有通讯实时排行榜和一些定制化的服务。
1)自研SQL
接下来说我们自研SQL的过程,我们早期为了避免像Hive一样,而我们自己通过SQLPaser的语法抽象后,把它生成一段函数,就不需要这么多的对账调用。
这个是函数生成过程,最终生成的就是这样一段代码,它去做计算逻辑,一个函数完成,不需要函数栈的调用,这样效率就会大大提升。我们原来单核跑八万,放在现在可以跑二十多万。
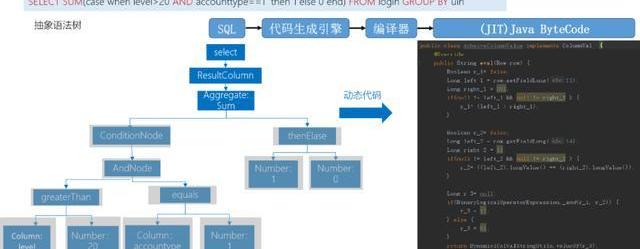
整个处理的时候,我们把sql编译成字节码,Flink消费了数据后,把数据转化成sql能够执行的函数,就是roll的方式。然后把Roll整个数据传到class里去执行,最后输出。
这种场景适合于,比如flinksql它有状态值,我们要统计某个最大值的话,要一直把用户的最大值hold到内存里去。而我们自研的SQL呢,自己写的函数,它把数据借助第三方存储,比如刚才说的TRedis存储。每次只需要读取和写入数据即可,不需要做过多的内存的hold。
当前做到状态的实时落地,就算挂掉也能立马起来接着去执行,所以超过10G、100G的数据计算,都不成问题,但是Flinksql如果要算的话,它的状态值就一直要hould到内存里去了,而且挂掉后只能用它的checkpoint去恢复。
所以这是这两种SQL的应用场景。
2)SQL化

另外SQL里我们还可以做些其他的事情。我们的数据是持久化保存在存储里的,那存储里如果是同一张表,同一个纬度,比如我们都是用QQ,在这个纬度上我们配置了两个指标,那能不能一次算完?只消费一次把数据算完,然后存储一次。
其实这种在大数据计算里是很多的,目前在我们在做的平台化就可以,比如一个是计算登录次数,另一个是计算最高等级,这两个计算逻辑不一样,但是消费的数据表是一样的,然后聚合纬度也是一样的,聚合关键字也是一样。那这个数据就可以进行一次消费,同时把数据计算出来同时去落地,大大减少了存储和计算成本。
我们现在整个游戏里面有一万一千多个指标,就是计算出来的,存储的纬度有两千六百多,实际节省计算和存储约有60%以上。
两个SQL,甚至更多的SQL,我们一张表算十几个指标很正常,原来要消费十几次现在只需要一次就可以算出来。而且这种情况对用户是无感知的。A用户在这张表上配了指标是A纬度,B用户在这张表上配了指标也是A纬度,那这两个用户的数据,我们在底层计算的时候就消费一次计算两次存储一次,最终拿到的数据也是一样的。
3)在线实时编程
无需搭建本地开发环境;
在线开发测试;
CreatorDAO完成2000万美元种子轮融资,a16z和Initialized Capital领投:8月9日消息,CreatorDAO完成2000万美元种子轮融资,a16z和Initialized Capital领投,Paris Hilton和音乐家The Chainsmokers等参投。据悉,CreatorDAO投资于创作者,以换取他们未来收入的一定比例,DAO结构允许众包投资决策,并奖励对DAO的贡献。(CoinDesk)[2022/8/10 12:13:57]
严格的输入输出管理;
标准化输入和输出;
一站式开发测试发布监控。
再介绍下刚才提到的在线实时编程,其实很多时候对开发者来说,搭建一个本地的Flink集群做开发调测也是非常麻烦的,所以我们现在就是提供一种测试环境,上层的代码都是固定的,不能修改。比如数据已经消费过来了,进行数据的加工处理,最终往存储里去塞就可以了。
通过这种方式,我们可以对简单逻辑进行分装,需要函数代码,但比SQL复杂,比自动的Jar包开发要简单一些,可以在线写代码,写完代码直接提交和测试就能完成结果的输出。而且这种的好处是,数据的上报逻辑,数据的统计逻辑,我都在这里面分装好了。只要管业务逻辑的开发就好了。
4、Flink特性应用
时间特性:基于事件时间水印的监控,减少计算量,提高准确性;
异步化IO:提高吞吐量,确保顺序性和一致性。
我们最早在Strom里做的时候,数据产生的时间和数据进到消息队列的时间,都是通过这种消息里自带的时间戳,每一个消息都是要对比的。有了Flink之后,有了watermark这个机制之后,这一部分的计算就可以减少了。
实际测试下来的效果也是比较理想的,我们原来在Storm里单核计算,大概是以前的QPS,加上读写和处理性能,单核五个线程的情况下。但是Flink的时候我们可以到一万,还加上Redis存储IO的开销。
另一个我们原来数据想要从Redis里取出来,再去算最大值最小值,完了算了再写到Redis里,这个都是同步去写的,但是同步IO有一个问题就是性能不高。
所以我们现在在把它改成异步IO,但是异步IO也有个特点就是整个一条数据的处理必须是同步的,必须先从Redis里把数据取出来,然后再把值计算完,再塞到里面去,保证塞完后再处理下一个统一的数据。
我们再做这样的一些优化。Flink这里有些特性可以保证我们数据的一致性,而且提升效率。
5、统一大数据开发服务—服务案例
接着介绍下更多的案例,如果大家玩英雄联盟的话,那这个任务系统就是我们设计的,下次玩做这个任务的时候,你就可以想起我。还有天龙八部、CF、王者荣耀LBS荣耀战区、王者荣耀的日常活动、有哪些好友是实时在线的,跟你匹配的。
三、数据接口服务OneFun
1、数据应用的出口
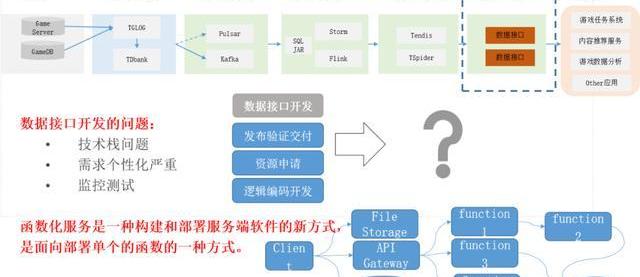
下面介绍下函数,我们原来在做的时候也是存在着一些问题,把数据存到存储里面,如果存储直接开放出去,让别人任意去使用的话,其实对存储的压力和管理程度都是很有问题的。所以后来我们采用了一种类似于Fass的的解决方式。我们把存储在里面的元数据进行管理,完了之后接口再配置化的方式,你要使用我这个DB,这个DB最大QPS多少,我就进行对比,允许你之后才能使用这个量。
比如我这个DB的最大QPS只有10万,你要申请11万,那我就给你申请不了,我就只能通知DB把这个Redis进行扩容,扩容后才给你提供使用。
所以这里面牵扯到我们的指标数据的元数据管理和接口之间的打通。
2、一体化函数执行引擎—OneFun
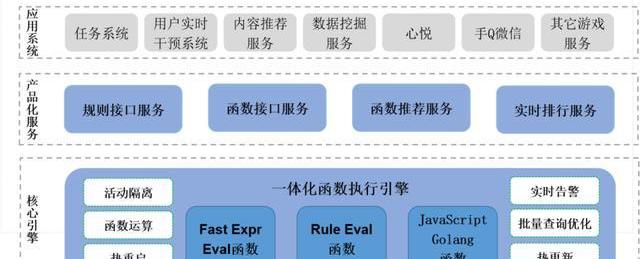
这个和刚才OneData的方式是一样的,比如这块提供了快速的函数,还有一些在线函数编程的方式的接口,你可以在上面写一点JavaScript或者Golang代码,然后就生成接口,接口里面可以直接对外提供服务,把他形成产品化的包装,在上层根据接口衍生出更多其他的一些应用系统。
3、基于ssa的在线golang函数执行引擎

这里重点介绍下golang,其实我们是基于golang语言本身ssa的特点去做的,我们有一个执行器,这个执行器已经写好的,它的作用就是可以把你写的golang代码提交过来,加载到它的执行器里。
并且我们可以把我们写的代码作为函数库,积累下来然后放进去,它可以在执行的时候去调用这些函数库,而这里面写的代码语法和golang是完全一样的。
同时我们在这里面执行的时候,指定了一个协程,每一个协程我们规定它的作用域,就是以沙箱机制的方式来去执行,最先实现的就是外部context去实现的,我们就可以实现web化的golang开发,这种有点像lua那种脚本语言一样,你在线写完语言直接提交执行。
4、基于V8引擎的在线函数服务引擎
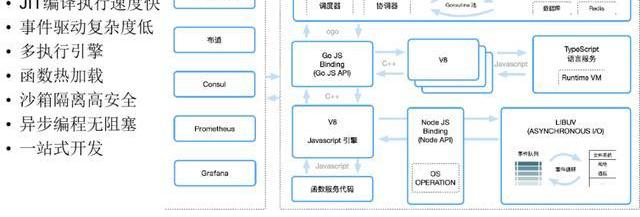
这是我们的javascript的执行引擎,我们主要是做了V8引擎的池子,所有javascript写完之后,丢到V8引擎上去执行,这应该大家都能够理解,如果大家玩过JS的可以理解这种方式,就是V8引擎里直接去执行。
5、一体化函数执行引擎--函数即服务
这是我们的在线函数编写过程:
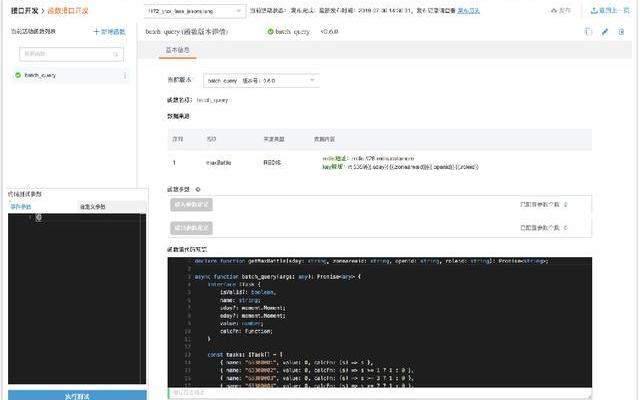
右下角是我们的函数代码编写区,写完后左边的黑框是点击测试,输出可以在这里写,点击测试就会把结果输出出来,通过这种方式,我们极大地扩张了我们数据平台的开发能力。原来是本地要把golang代码写完,然后调试完再发到线上环境去测试,而现在我们可以很大的规范化,比如说数据源的引入,我们就直接可以在这里去规定了,你只能引入申请过的数据源,你不能随便乱引入数据源,包括你数据源引入的时候,QPS放大我都可以通过这种方式知道。
降低启动成本;
更快的部署流水线;
更快的开发速度;
系统安全性更高;
适应微服务架构;
自动扩展能力。
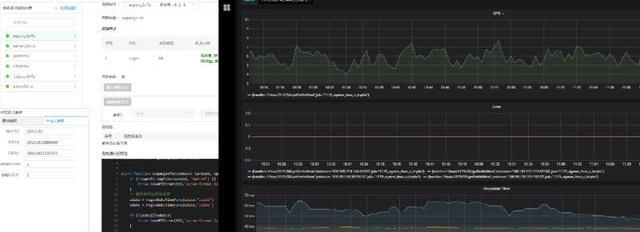
这个是我们一站式,把函数开发完后,直接提交,我们用Prometheus+grafana可以里面看到实时报表。
6、案例介绍

这是一个典型的应用,Flink里面去计算的时候,他对这个数据进行过滤,完了之后进行一个远程的call,这个远程调用执行函数代码,大多数这种情况就是一个开发就可以完成大数据的开发和这个函数接口的开发,就可以完成这样一个活动的开发,整个活动开发的门槛就低了很多,真正实现了我们DevOps,就是开发能够把整个流程自己走完。
四、微服务化&ServiceMesh
1、数据应用必走之路—微服务化
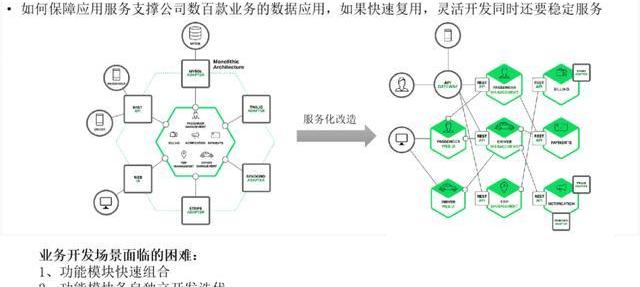
上面讲的是OneData和OneFun的实现原理和机制,我们在内部是怎么去应用的,这套系统我们在游戏内部是大力推广。
这里尤其是接口这块,其实如果说要微服务化的话,大数据我们能做的也就是那样了,能够用yarn或者K8S去做资源的管控,和任务的管控,但真正去做服务治理还是在接口这块。目前我们上下接口大概是三千五百个,每周新增50个接口。
所以我们在做的时候也考虑到。原来我们服务是一个个开发,但是没有治理,现在我们加上服务还是一个个去开发,甚至有些服务我们会把它变成一个服务,但是我们加入了这个服务的治理。
好多人在提微服务,微服务如果没有一个平台去治理的话,将会是一种灾难。所以微服务化给我们带来便利的同时,也会给我们带来一些问题,所以在我们的场景里面,微服务是非常好的,每一个接口就可以作为一个服务,这种是天然的微服务。
2、一体化服务治理设计
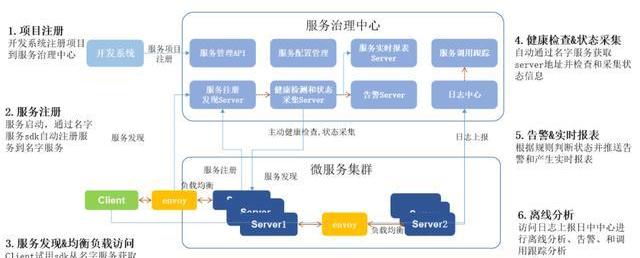
但是这种微服务的治理将会是我们很大的一个问题,所以我们花了很大的精力去做了一个微服务的治理系统,从项目注册的时候,他就把项目注册的微服务中心,并且把API注册上来,然后在服务发布的时候,发到集群里的时候,这些服务都要主动的注册到我们的名册服务,就是Consoul。
但注册到服务里不是作为服务路由来用的,而是到服务里后,我们在普罗米修斯这块去做它的健康检查和状态采集,只要注册上来,我立马就能感知和把状态采集过来,然后主要做实时报表和告警。
首先在服务的稳定性和健康度这块我们有一个保障,另外一个就是服务的信息注册到Consul里去后,我们有一个服务的网关,我们用的是envoy,其实内部我们还把它作为SideCar使用,后面会介绍。
注册完了之后,envoy会把这个所有的负载进信息加载到这块来,它去做它服务的路由,同时我们会把整个日志上报到日志中心去,包括网关的日志也会上传到日志中心去,日志中心再去做离线的报表和实时的一些报警监控,
所以这里面我们还加了一个基于Consul的一个配置,就是我们包括server的实时控制都可以通过Consul去配置,配置完了后立马能够watch到,然后去执行。
这个是基本的服务治理,但现在我们的服务治理升级了,比这个要更好一点,基本的原理是这样。
3、南北流量+东西流量的统一管控
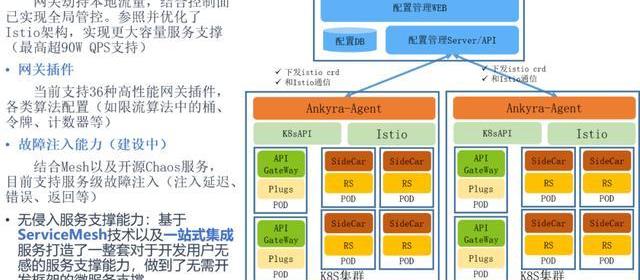
并且我们在这里面实现了一个对envoy的管控,我们说是服务治理,主要是对流量的一些治理,比如贫富负载策略,路由策略,熔断,超时控制,故障注入等等一系列。
我们是通过Consul的配置管理,通过它能够下发到我们的Agent,这个Agent再把这个数据能够通过Istio的接口和k8s的API能够下发到envoy,这里面就是APIGeteWay和SideCar都是envoy,所以我们通过Istio对他的XDS的接口写入,就可以把所有的配置信息下发到这里。
这套系统能够整个去管控整个集群,南北流量和东西流量的统一管控。这套系统我们未来准备开源,现在主要是内部在使用,而且这里面我们也做了图形化的配置,所有envoy和Istio的配置我们都经过YAML转Istio再转UI的方式,把它图形化了,在这块能够做统一的管控。
而且我们把Agent开发完了之后就是多集群的支持,就是多个K8s集群只要加入进来,没问题可以去支持,我们管理APIGeteWay。
还有一块是SideCar的管理,就是ServiceMash里的SideCar管理。我们刚才说的函数接口也好,规则接口也好,是一个server。
当然这里面还提到一个chaosmesh的功能,我们现在还在研究,我们准备在这套系统里把它实现了。
4、基于ServiceMesh的全链路流量分析
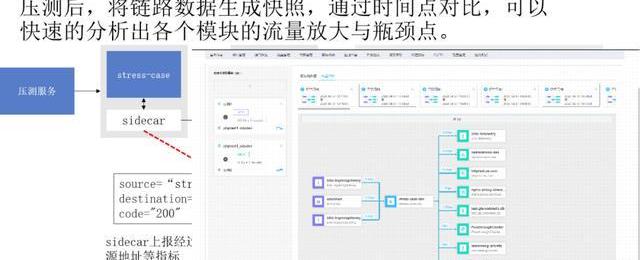
这是一个我们通过ServiceMesh做的分析,我们虽然可以宏观地看出来我们接口对DB的压力有多大,但实际上我们把流量导进来是我们对压力的监控是不够的,所以这种情况我们通过ServiceMesh,他对出口流量和进口流量的管控,然后可以把流量进行详细的统计,统计完后可以生成一个快照,这次快照和下次快照之间的数据对比,入流量有多少的时候,对下面各个流量压力有多少。
这是整个展示图,我们有多个测试用例,这两个测试用例之间我们可以算出来对下游的压力的流量分析,后期对下游压力的分析和下游资源的扩容、缩容都有非常大的价值。
5、案例介绍
最后再介绍下我们目前用这套系统实现的一些案例,大数据的游戏回归,比如做一个游戏数据的回顾、任务系统、排行榜。
>>>>
Q&A
Q1:servicemesh是怎么部署的?主要用来解决什么问题?
目前我们在使用的ServiceMesh技术实现是istio,版本是1.3.6。这个版本还不支持物理机方式部署,所以我们是在k8s中部署使用,部署方式有2种,可以是直接使用istioctl命令安装,或者是生成yaml文件后使用kubectl进行安装。
Servicemesh的架构主要解决的问题是集群内东西流量的治理问题。同时servicemesh的Sidercar作为协议代理服务和可以屏蔽后面的服务开发技术栈,Sidercar后面的服务可以是各种语言开发,但是流量的管理和路由可以有统一的管控。
Q2:微服务治理架构能介绍一下吗?
微服务治理架构在我看来可以分为两类:
服务实例的治理,这个在目前的k8s架构下,基本都是由k8s来管理了,包含了服务实例的发布,升级,阔所容,服务注册发现等等;
服务流量的治理,这一个大家通常说的服务治理,目前主要是由微服务网关和服务网格两种技术来实现。服务网关实现集群内和集群外的流量治理,服务网格实现了集群内的流量治理。
Q3:开发人员主要具有什么样的技术背景?
针对大数据开发人员,要使用我们这套系统只需要会sql语句和基本统计知识就可以了。
针对应用接口开发人员,要使用我们这套系统只需要会JavaScript或者Golang,会基本的正则表达式,了解http协议,会调试http的api接口就可以了。
Q4:实时计算,flink与spark选择上有没啥建议?
Spark在15,16年的时候我们也在大规模使用,也在实时计算中使用过,但是当时的版本在实时计算上还是比较弱,在500ms的批处理中还是会出现数据堆积,所以在实时性上会有一定的问题,Spark擅长在数据迭代计算和算法计算中。但是如果实时性要求不高而且有算法要求的场景中Spark还是不错的选择。
Flink在设计之初就是一种流失处理模型,所以在针对实时性要求较高的场景中Flink还是比较合适的,在我们内部测试发现Flink的流失计算吞吐确实要比Storm好很多,比Spark也是好很多,而且Flink目前的窗口机制针对实时计算中的窗口计算非常好用。所以一般实时计算或者对实时性要求较高的场景Flink还是比较推荐的。
Q5:游戏回放数据服务端存储场景有么?
这种场景也是有的,游戏回放一般有2种方式,一种是录屏传输回放,这种成本非常高,但是简单且及时性比较好,另外一种是控制指令发回Server,在另外的服务中去恢复当时的场景,这种方式在成本相对较小,但是使用复杂。
Q6:回放场景下客户端走什么协议将数据发送到服务端?
一般是游戏的私有协议。
如题,答案是真的! 但可是问题来了,仔细看下文。马来西亚公民在政府公立医院就医,只需花费1元马币挂号费,无论什么病,其它的费用由政府承担.
1900/1/1 0:00:00天眼查App显示,9月25日,浙江辛起新零售有限公司成立,注册资本1000万人民币,法定代表人为章利民.
1900/1/1 0:00:00自1985年《僵尸先生》爆火开始,导演刘观伟以每年一部的速度,连续产出僵尸电影。1986年拍了《僵尸家族》,1987年执导《灵幻先生》,1988年的《僵尸叔叔》则是其中唯一一部没有林正英参与的影.
1900/1/1 0:00:00Uniswap如今是DeFi项目中巨无霸的存在。根据DeFiPulse的统计数据,当前锁仓量约为1.6亿美元。而根据DeBank的数据统计显示,过去24小时,成交额高达2.15亿美元.
1900/1/1 0:00:001.阅读理解 Whenwasthelasttimeyouusedplasticplates?Nexttime.
1900/1/1 0:00:00商务部官网最新发布的通知,数字人民币在京津冀、长三角等地区开展试点。数字货币开启了内测,一连串问题也接踵而至:什么是数字货币?在什么场景下使用它?数字货币和比特币、支付宝、微信支付有什么区别?数.
1900/1/1 0:00:00